Глава 1. Обзор Linux Virtual Server
Linux Virtual Server (LVS) - это набор интегрированных программных компонентов для распределения нагрузки между несколькими реальными серверами. LVS работает на двух одинаково настроенных компьютерах: один из них явлается активным LVS-маршрутизатором, а второй- резервным LVS-маршрутизатором. Активный LVS-маршрутизатор выполняет две задачи:
Резервный LVS-маршрутизатор отслеживает состояние активного LVS-маршрутизатора и берет на себя функции последнего в случае выхода его из строя.
В этой главе представлен обзор компонентов и функций LVS. Глава состоит из следующих разделов:
1.1. Простая конфигурация Linux Virtual Server
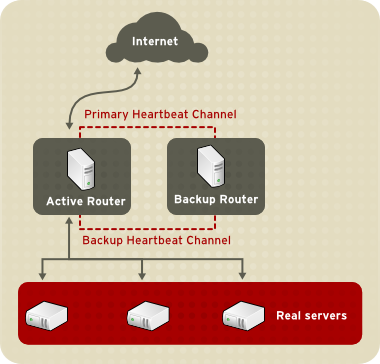
На рисунке
Рисунок 1.1. Простая конфигурация Linux Virtual Server” показана простая конфигурация LVS, состоящая из двух уровней. На первом уровне расположены два LVS-маршрутизатора - активный и резервный. Каждый LVS-маршрутизатор имеет два сетевых интерфейса, один для внешней сети (Интернет) и один для внутренней сети, что позволяет контролировать трафик между двумя сетями. В этом примере активный LVS-маршрутизатор использует
Network Address Translation или
NAT для распределения трафика из внешней сети между произвольным количеством реальных серверов, расположенных на втором уровне и, в свою очередь, предоставляющих доступ к необходимым сервисам. Реальные серверы в этом примере подключены к выделенному сегменту внутренней сети и направляют весь внешний трафик обратно через активный LVS-маршрутизатор. Для пользователей внешней сети все серверы выглядят как единое целое.
Запросы к сервисам, приходящие на LVS-маршрутизаторы, отправлены на
виртуальные IP-адреса, или
VIP (Virtual IP). Это публично маршрутизируемые адреса, ассоциированные администратором сайта с определенным доменным именем, например, www.example.com, и выделенные под один или несколько
виртуальных серверов. Виртуальный сервер - это сервис, настроенный на прослушивание выделенного виртуального IP. Для получения подробной информации о настройке виртуальных серверов при помощи
Piranha Configuration Tool обратитесь к странице
4.6. Раздел “VIRTUAL SERVERS”. VIP-адреса мигрируют с одного LVS-маршрутизатора на другой в случае возникновения сбоев, обеспечивая таким образом доступность IP-адресов (известных также как
плавающие IP-адреса).
VIP-адреса могут быть псевдонимами того же устройства, с помощью которого LVS-маршрутизатор подключен к Интернет. Например, если интерфейс eth0 подключен к Интернет, то несколько виртуальных серверов может быть ассоциировано с eth0:1. В качестве альтернативы, каждый виртуальный сервер может быть ассоциирован с отдельным устройством. Например, HTTP-трафик может обрабатываться на интерфейсе eth0:1, а FTP-трафик - на eth0:2.
В любой отдельно взятый момент времени активен только один LVS-маршрутизатор. Одной из основных задач активного LVS-маршрутизатора является перенаправление запросов, поступающих на виртуальные IP-адреса, к реальным серверам. Перенаправление основывается на одном из восьми поддерживаемых алгоритов балансировки нагрузки. Эти алгоритмы описаны в разделе
1.3, “Обзор планировщика LVS”.
Активный маршрутизатор также динамически отслеживает текущее состояние сервисов на реальных серверах при помощи простых send/expect-скриптов. Для определения состояния таких сервисов, как HTTPS или SSL, администратор имеет возможность вызывать внешние исполняемые файлы. Если сервис на реальном сервере отказывает, активный маршрутизатор перестает перенаправлять запросы на этот сервер до тех пор, пока сервис не начнет функционировать нормально..
Периодически активный и резервный LVS-маршрутизаторы обмениваются heartbeat-сообщениями через основной внешний интерфейс, а в случае сбоя - через внутренний интерфейс. Если резервный узел не может получить heartbeat-сообщение в течение заданного интервала времени, он инициирует процедуру восстановления после отказа и берет на себя роль активного маршрутизатора. Во время процедуры восстановления после отказа резервный маршрутизаторе активизирует VIP-адреса, облуживавшиеся ранее отказавшим маршрутизатором, используя метод, известный как ARP spoofing. В ходе этой процедуры резервный LVS-маршрутизатор объявляет себя получателем всех IP-пакетов, адресованных сбойному узлу. После того, как отказавший узел вновь начинает нормально функционировать, резервный узел возвращается в свое исходное состояние.
Поскольку отдельные виртуальные серверы в двухуровневой конфигурации, показанной на
Рисунке 1.1., не осуществляют автоматическую синхронизацию данных между собой, это решение является оптимальным для случаев, когда данные на реальных серверах изменяются не очеь часто, например, это могут быть статичные web-страницы.