Возможности кластера
Кластер строится на следующих принципах:
Аппаратная конфигурация, не имеющая одиночной уязвимой точки.
Кластеры могут использовать RAID массив с двумя контроллерами, несколько каналов соединения по сети и через последовательные порты, дублирующие бесперебойные блоки питания (UPS), гарантируя таким образом, что поломка одного компонента системы не приведет к остановке кластера или потере данных.
Напротив, кластеры низкой ценовой категории не предоставляют такого высокого уровня отказоустойчивости. Например, администратор может построить кластер, используя RAID-массив, с одним контроллером, и один пульсирующий канал.

Замечание Некоторые недорогие альтернативы, например, программный RAID или одну SCSI-шину с несколькими инициаторами, нельзя использовать для реализации в кластере общего хранилища. Обратитесь к разделу Выбор конфигурации оборудования в Главе 2 за дополнительной информацией.
Схема конфигурации службы
Кластеры позволяют администратору легко настраивать отдельные службы для обеспечения высокой степени доступности данных и приложений. Создавая службу, администратор указывает ресурсы, используемые службой, её свойства, включая имя службы, сценарии запуска и остановки приложения, дисковые разделы, точки подключения и кластерную систему, в которой администратор предпочитает выполнять эту службу. Когда администратор создаёт службу, кластер добавляет эту информацию в базу данных кластера на общем диске, к которому затем смогут обращаться все кластерные системы.
Кластер предоставляет легкую в использовании схему для приложений баз данных. Например, служба базы данных предоставляет приложению данные высокой степени доступности. Приложение, работающее в кластерной системе, предоставляет сетевой доступ к базе данных своим клиентам, например Web-серверам. Если служба переносится на другую кластерную систему, приложение по-прежнему может обращаться к общей базе данных. Сетевой службе базы данных обычно назначается IP адрес, который переносится вместе со службой, таким образом сохраняется прозрачный доступ клиентов к данным.
Схема кластерной службы также может расширяться и использоваться в других приложениях.
Обеспечение целостности данных
Для обеспечения целостности данных, в определенный момент времени только один узел кластера выполняет службу и обращается к данным службы. Использование переключателей питания в кластере позволяет одной кластерной системе выполнить отключение и включение питания другой, до переноса её служб. Это предотвращает одновременное обращение двух систем к одним и тем же данным, тем самым обеспечивается сохранность данных. Хотя это и не требуется, рекомендуется использовать переключатели питания для обеспечения сохранности данных при сбое в любых условиях. Сторожевые таймеры также представляют собой необязательный элемент системы управления питанием, обеспечивающий корректное выполнение операции переноса службы.
Пользовательский интерфейс управления кластером
Пользовательский интерфейс упрощает управление кластером и позволяет администратору легко создавать, запускать, останавливать и перемещать службы, а также наблюдать за работой кластера.
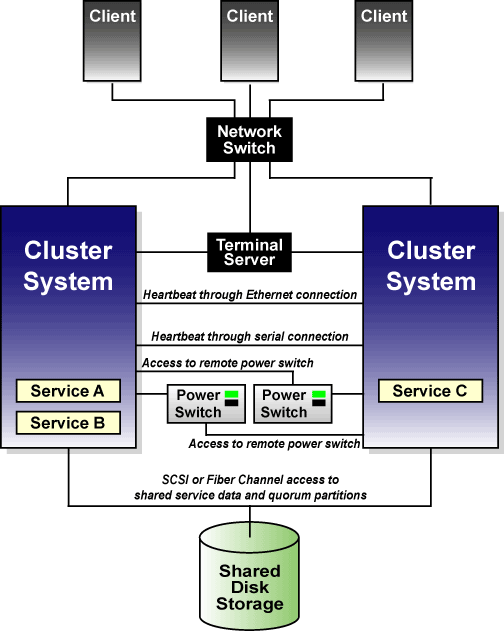
Различные варианты соединений между кластерными системами
Для контроля состояния другой системы, каждая кластерная система наблюдает за работой удаленного переключателя питания (если он используется), а также отправляет пульсирующие пакеты по сетевому интерфейсу и через последовательный порт. Кроме этого, каждая кластерная система периодически записывает отметку времени и информацию о состоянии кластера в два кворумных раздела, расположенных на общем диске. В информации о состоянии системы также фиксируется, является ли система активным членом кластера. В информации о состоянии службы отмечается, работает ли определенная служба, и если да, то на какой из кластерных систем. Каждая кластерная система проверяет, является ли актуальным состояние другой системы.
Если система при загрузке не сможет записать состояние в оба кворумных раздела, ей не будет позволено включиться в кластер, что обеспечивает корректную работу кластера. Кроме этого, если кластерная система вовремя не изменила свою отметку времени, и пульсирующий канал этой системы не работает, эта система исключается из кластера.
На рисунке 1-2 показано, как в конфигурации кластера соединяются системы. Обратите внимание, терминальный сервер, используемый для подключения к системам через последовательные порты, не является обязательным компонентом кластера.
Возможность переноса службы
Если происходит сбой программы или оборудования, кластер предпримет необходимые действия для поддержания доступности приложения и целостности данных. Например, если произойдет полная остановка кластерной системы, другая кластерная система запустит её службы. Службы, уже работающие в этой системе, при этом не затрагиваются.
Когда отказавшая система перезагрузится и сможет произвести запись в кворумные разделы, она снова сможет войти в кластер и выполнять службы. В зависимости от конфигурации служб, кластер может также распределять нагрузку между двумя кластерными системами.
Возможность ручного перемещения служб
Помимо автоматического переноса службы, кластер позволяет администратору безболезненно вручную останавливать службы в одной кластерной системе и запускать в другой. Это позволяет администраторам выполнять запланированное техническое обслуживание кластерной системы, в то же время сохраняя доступность приложений и данных.
Возможность отслеживания событий
Для того чтобы администратор смог выявить и решить проблемы, до того как они повлияют на работу системы, кластерные демоны при помощи стандартной подсистемы Linux syslog записывают сообщения о них в протокол. Администраторы могут задавать уровень важности сообщений, попадающих в протокол.
Наблюдение за приложением
Инфрастуктура кластерных служб может также наблюдать за состоянием и работой приложения. Таким образом, если в работе приложения произойдет сбой, кластер автоматически перезапустит это приложение. В качестве реакции на сбой приложения, приложение сначала будет перезапущено на том же узле кластера, а если это не исправит ситуацию, в другой кластерной системе.
Агент наблюдения за состоянием
Агент, наблюдающий за состоянием кластера, собирает и анализирует важную информацию о состоянии кластера и приложений. Собранная им информация становится доступной и в локальной кластерной системе и удаленно. Затем в графической среде управления можно просмотреть информацию о состоянии сразу нескольких кластеров, не снижая при этом производительность системы.