1.4. Установка и подключение оборудования кластера
Установив Red Hat Enterprise Linux, настройте всё оборудование кластера и проверьте, определила ли операционная система все подключенные устройства. Обратите внимание, набор действий, необходимых для настройки оборудования, может меняться в зависимости от вашей конфигурации. За дополнительной информацией о конфигурациях кластера обратитесь к разделу 1.1 Выбор конфигурации оборудования.
Чтобы настроить кластерное оборудование, выполните следующие действия:
Отключите узлы кластера и отсоедините их от источника питания.
Настройте связанные Ethernet-каналы, если они используются. За дополнительной информацией обратитесь к разделу 1.4.1 Настройка связанных Ethernet-каналов.
Если в вашей конфигурации применяются переключатели питания, настройте их и подсоедините к ним узлы кластера. За дополнительной информацией обратитесь к разделу 1.4.2 Настройка переключателей питания.
Кроме этого, рекомендуется подключать каждый переключатель питания (или кабель питания узлов, если переключатель питания не используется) к разным системам UPS. За информацией об использовании дублирующих систем UPS обращайтесь к разделу 1.4.3 Настройка систем бесперебойного питания.
Настройте общее дисковое хранилище в соответствии с инструкциями производителя и подключите к нему узлы кластера. За дополнительной информацией о выполнении этой задачи обратитесь к разделу 1.4.2 Настройка общего дискового хранилища.
Кроме этого, рекомендуется подключать внешнее хранилище к дублирующим системам UPS. За дополнительной информацией о дублирующих системах UPS обращайтесь к разделу 1.4.3 Настройка систем бесперебойного питания.
Включите питание оборудования и загрузите все узлы кластера. Во время загрузки компьютера, войдите в настройки BIOS и измените его настройки следующим образом:
Убедитесь в том, что идентификационный номер SCSI, используемый SCSI-адаптером уникален для шины SCSI, к которой он подключен. За дополнительной информацией о выполнении этой задачи обратитесь к разделу B.5 Идентификационные номера SCSI.
Включите или отключите терминаторы шины для каждого SCSI-контроллера, как того требует конфигурация внешнего хранилища. За дополнительной информацией о выполнении этой задачи обратитесь к разделу 1.4.4 Настройка общего хранилища и разделу B.3 Терминаторы шины SCSI.
Настройте узел так, чтобы при включении он загружался автоматически.
Выйдите из утилиты BIOS и продолжите загрузку каждого узла. Проверьте сообщения загрузки, убедитесь в том, что ядро Red Hat Enterprise Linux настроено правильно и определило полный набор общих дисков. Воспользуйтесь командой dmesg для просмотра консольных сообщений о загрузке. В разделе 1.3.3 Отображение консольных сообщений о загрузке вы найдёте дополнительную информацию о команде dmesg.
Убедитесь в том, что узлы могут связаться друг с другом через Ethernet канал точка-точка, выполнив команду ping для каждого сетевого интерфейса.
Настройте общие разделы кластера на общем дисковом хранилище. За дополнительной информацией о выполнении этой задачи обратитесь к разделу 1.4.4.3 Настройка общих разделов кластера.
1.4.1. Настройка связанных Ethernet-каналов
Связывание каналов Ethernet в кластере без одиночной уязвимой точки позволяют получить отказоустойчивое сетевое соединение путем объединения двух устройств Ethernet в одно виртуальное устройство. Полученный интерфейс, связывающий каналы, гарантирует, что в случае отказа одного устройства Ethernet будет активизировано другое. Такой тип связывания каналов, так называемая политика активный-резервный позволяет подключить оба связанных устройства к одному коммутатору, а также подключить каждое устройство Ethernet к отдельному коммутатору или концентратору, что ликвидирует одиночную уязвимую точку, какую представляет из себя один коммутатор.
Для связывания каналов требуется, чтобы на каждом узле кластера были установлены два Ethernet-адаптера. Когда оно активно, модуль связывания использует MAC-адрес первого задействованного устройства и, в случае, если его соединение разрывается, назначает этот MAC-адрес другому сетевому устройству.
Чтобы настроить связывание каналов, используя два сетевых устройства, выполните следующее:
Опишите связывающие устройства в файле /etc/modules.conf. Например:
alias bond0 bondingoptions bonding miimon=100 mode=1
При этом будет запущено связанное устройство с именем интерфейса bond0 и драйверу связывания будут переданы параметры, настраивающие главное устройство в конфигурации активный-резервный для задействованных сетевых интерфейсов.
Отредактируйте файлы конфигурации /etc/sysconfig/network-scripts/ifcfg-ethX для устройств eth0 и eth1 так, чтобы файлы выглядели одинаково. Например:
DEVICE=ethX USERCTL=no ONBOOT=yes MASTER=bond0 SLAVE=yes BOOTPROTO=none
При этом устройство ethX (замените X номером соответствующего устройства Ethernet) будет задействовано для главного устройства bond0.
Создайте файл конфигурации для связанного устройства (например, /etc/sysconfig/network-scripts/ifcfg-bond0), который будет выглядеть примерно так:
DEVICE=bond0 USERCTL=no ONBOOT=yes BROADCAST=192.168.1.255 NETWORK=192.168.1.0 NETMASK=255.255.255.0 GATEWAY=192.168.1.1 IPADDR=192.168.1.10
Перезагрузите компьютер, чтобы изменения вступили в силу. Можно сделать и по-другому, вручную загрузив поддержку связанного устройства и перезапустив сеть. Например:
/sbin/insmod /lib/modules/`uname -r`/kernel/drivers/net/bonding/bonding.o \ miimon=100 mode=1
/sbin/service network restart
1.4.2. Настройка переключателей питания
Переключатели питания позволяют одному узлу отключить питание другого узла, до запуска его служб во время переноса. Возможность удалённого отключения/включения питания узла гарантирует сохранение целостности данных при сбое в любых условиях. Рекомендуется при реализации кластеров в производственной среде использовать переключатели питания или сторожевые таймеры. Только в среде разработки (тестовой) допускается использование конфигурации без переключателей питания. Описание различных типов переключателей питания вы найдёте в разделе 1.1.3 Выбор типа контроллера питания. Заметьте, в этом разделе понятие "переключатель питания" включает в себя также сторожевые таймеры.
В кластерной конфигурации, использующей аппаратные переключатели питания, кабель питания каждого узла подключается к переключателю питания. При сбое одного узла кластера, другой может отключить питание первого, до запуска её служб.
Переключатели питания защищают данные от искажения, в случае если не отвечающий (или "зависший") узел неожиданно продолжит свою работу, после того как все его службы оказались перенесены, и попытается выполнить запись на диск, одновременно с другим узлом. Кроме этого, если на узле кластера останавливается демон кворума, данный узел больше не сможет наблюдать за общими разделами кластерами. Если вы не используете в кластере переключатели питания или сторожевые таймеры, при описанных выше условиях, служба может начать работу сразу на нескольких узлах кластера, что может привести к разрушению данных и, возможно, отказу системы.
Настоятельно рекомендуется использовать в кластере переключатели питания. Однако, администраторы, хорошо понимающие последствия такого решения, могут построить кластер без переключателей питания.
Узел может зависнуть на несколько секунд во время подкачки страниц или при большой нагрузке. Именно поэтому, необходимо подождать некоторое время, до того как прийти к заключению об отказе узла (обычно 15 секунд).
Если узел определяет, что его партнёр остановился, и в кластере используются переключатели питания, этот узел отключает повисший узел до перезапуска его служб. Узлы кластера, использующие сторожевые таймеры, в большинстве случаев при зависании перегружаются самостоятельно. Таким образом, повисшая система перезагрузится, предотвратив тем самым обмен данными с хранилищем и их искажение.
Повисшие узлы перегружаются самостоятельно при срабатывании сторожевого таймера, сбое отправки пульсирующих пакетов, или при ошибке получения состояния кворума (если для этого узла не используется физический переключатель питания).
Повисшие узлы могут быть перегружены другими узлами, если они подключены к переключателю питания. Если повисший узел сам не сможет продолжить нормальную работу, и вы не используете переключатели питания, вам придётся перезапустить его вручную.
Если вы используете переключатели питания, вы должны настроить их в соответствии с инструкциями производителя. Кроме этого, для использования переключателей питания в конкретном кластере, могут понадобиться дополнительные настройки. Обратитесь к разделу B.1 Настройка контроллеров питания за подробной информацией о переключателях питания (включая сторожевые таймеры). Обратите внимание на все тонкости использования и функциональные возможности приведённых переключателей питания. Заметьте, что информация, касающаяся кластера, представленная в этом руководстве, является более важной, чем предоставленная производителем.
При подключении переключателей питания убедитесь в том, что каждый кабель воткнут в соответствующую розетку. Это важно, так как программным путем проверить правильность подключения невозможно. Неправильное подключение кабелей может привести либо к случайному отключению функционирующего узла, либо к неверному заключению одного узла о том, что он успешно перегрузил другой узел.
Настроив переключатели питания, выполните следующие действия для подключения их к узлам кластера:
Подсоедините кабель питания каждого узла к переключателю питания.
Подключите каждый узел к переключателю питанию. Кабель, используемый при таком подключении, может различаться в зависимости от выбранного переключателя. Переключатели питания с последовательным интерфейсом подключается нуль-модемным кабелем, тогда как для подключения сетевых переключателей потребуется кабель Ethernet.
Подсоедините силовой кабель переключателей к источнику питания. Рекомендуется подсоединять переключатели питания к разным системам UPS. За дополнительной информацией обратитесь к разделу 1.4.3 Настройка систем бесперебойного питания.
Выполнив установку программного обеспечения кластера, до запуска кластера проверьте переключатели питания; сможет ли каждый узел перезагрузить другой. Как это сделать, описано в разделе 2.11.2 Проверка переключателей питания.
1.4.3. Настройка систем бесперебойного питания
Источники бесперебойного питания (UPS) обеспечивают надежный источник питания. Для реализации идеального отказоустойчивого кластера необходимо использовать несколько UPS (для каждого сервера свой). Для достижения максимальной отказоустойчивости можно подключить два UPS к одному серверу, и использовать автоматические переключатели питания APC для управления питанием сервера. Применение этих решений зависит от требуемого уровня доступности.
Не рекомендуется использовать одну инфраструктуру UPS в качестве единственного источника питания кластера. Выделенные для кластера UPS дадут большую гибкость с точки зрения управляемости и доступности.
Применяемая система UPS должна обеспечивать необходимое напряжение и мощность в течение продолжительного времени. Так как нет одной универсальной системы UPS, подходящей в любых ситуациях, выбор системы будет зависеть от конкретной конфигурации.
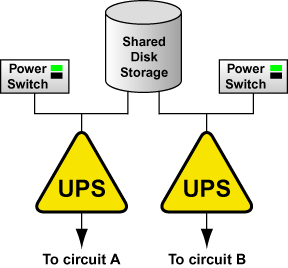
Если подсистема дискового хранилища подключается двумя отдельными кабелями питания, установите две системы UPS, и соедините каждый переключатель питания (или, если он не используется, просто кабель питания узла кластера) и кабель питания дискового хранилища с системами UPS. Конфигурация избыточной системы UPS показана на рисунке 1-3.
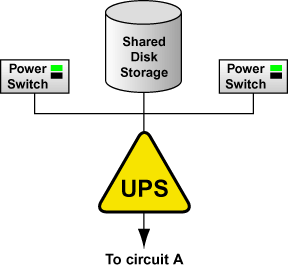
В качестве альтернативы можно подключить оба переключателя питания (или кабели питания узлов кластера) и подсистему дискового хранилища к одной системе UPS. Это более экономная конфигурация, обеспечивающая некоторый уровень защиты от отключения питания. Однако, если отключение всё же произойдет, одна система UPS становится одиночной уязвимой точкой. Кроме этого, одна система UPS может не иметь достаточной мощности для питания всех подключенных устройств в течение требуемого времени. Конфигурация с одной системой UPS показана на рисунке 1-4.
Многие системы UPS поставляются вместе с приложениями для Red Hat Enterprise Linux, позволяющими наблюдать за состоянием работы UPS через последовательное соединение. Если аккумуляторы разряжены, управляющее программное обеспечение выполняет корректное отключение системы. В этом случае, программное обеспечение кластера также будет остановлено, так как оно управляется сценарием уровня выполнения System V (например, /etc/rc.d/init.d/clumanager).
За подробной информацией по установке UPS обратитесь к документации, предоставленной производителем оборудования.
1.4.4. Настройка общего дискового хранилища
В кластере общее дисковое хранилище используется для размещения служебных данных и двух разделов (основной и теневой), хранящих информацию о состоянии кластера. Так как это хранилище должно быть доступно всем узлам, оно не может располагаться на дисках, зависящих от доступности какого-то одного узла. За подробной информацией о конкретном продукте и его установке обратитесь к документации производителя.
При установке в кластере общего дискового хранилища необходимо учитывать следующие факторы:
Внешний RAID
Настоятельно рекомендуется использовать RAID 1 (зеркалирование) для обеспечения высокой степени доступности данных службы и общих разделов кластера. По своему усмотрению, вы можете использовать RAID-массивы с чётностью, также обеспечивающие отказоустойчивость. Не используйте для общих разделов RAID 0 (чередование), так как это уменьшает степень их доступности.
SCSI-конфигурации с несколькими инициаторами
Такие конфигурации не поддерживаются ввиду сложности обеспечения соответствующего окончания шины.
Имена устройств общего хранилища в Red Hat Enterprise Linux должны быть одинаковыми на всех узлах. Например, устройство, имеющее название /dev/sdc на одном узле, на другом также должно называться /dev/sdc. При использовании во всех узлах кластера одинакового оборудования, обычно это требование выполняется.
Дисковый раздел может использоваться только одной кластерной службой.
Не добавляйте подключения файловых систем, используемых для работы кластера, в локальный файл /etc/fstab узлов, так как программное обеспечение кластера само управляет подключением и отключением файловых систем службы.
Для увеличения производительности общих файловых систем, определите размер блока равным 4 Кбайт, передав параметр -b команде mke2fs. При использовании блоков меньшего размера, fsck обычно работает дольше. Обратитесь к разделу 1.4.4.6 Создание файловых систем.
В следующем списке приведены более подробные требования к параллельной шине SCSI, которые следует соблюдать в кластерном окружении:
На обоих концах SCSI-шины должны быть установлены терминаторы, кроме этого шины должны соответствовать ограничениям длины, и возможно, "горячего" подключения.
Все устройства (диски, хост-адаптеры и RAID-контроллеры) на одной SCSI шине должны иметь уникальный идентификационный номер SCSI.
За дополнительной информацией обратитесь к разделу B.2 Требования к конфигурации шины SCSI.
Настоятельно рекомендуется подключать хранилище к дублирующим системам UPS, обеспечивающим надёжный источник питания. За дополнительной информацией обратитесь к разделу 1.4.3 Настройка систем бесперебойного питания.
Обратитесь к разделу 1.4.4.1 Настройка SCSI-шины с одним инициатором и разделу 1.4.4.2 Настройка соединения Fibre Channel за дополнительной информацией о настройке общего хранилища.
Настроив оборудование общего дискового хранилища, разбейте диски на разделы и создайте файловые системы или неформатированные устройства. Для общих разделов кластера (основного и теневого) необходимо создать два неформатированных устройства. За дополнительной информацией обратитесь к разделу 1.4.4.3 Настройка общих разделов кластера, разделу 1.4.4.4 Разбиение дисков на разделы, разделу 1.4.4.5 Создание неформатированных устройств, и разделу 1.4.4.6 Создание файловых систем.
1.4.4.1. Настройка SCSI-шины с одним инициатором
SCSI-шина с одним инициатором позволяет подключить к ней только один узел кластера, обеспечивая при этом изоляцию узлов и большую производительность, чем шина с несколькими инициаторами. Шины с одним инициатором гарантируют независимость одного узла от большой нагрузки, инициализации или наладки других узлов.
Используя RAID-массив с одним или двумя контроллерами, имеющий несколько портов и обеспечивающий одновременный доступ с этих портов ко всем общим логическим единицам хранилища, вы можете использовать шины SCSI с одним инициатором для подключения к RAID-массиву каждого узла кластера. Если логическая единица устройства переносится с одного контроллера на другой, это происходит незаметно для операционной системы. Обратите внимание, некоторые RAID-контроллеры ограничивают подключение к набору дисков определённым контроллером или портом. В этом случае невозможно использовать конфигурацию шины с одним инициатором.
Конфигурация шины с одним инициатором должна соответствовать требованиям, приведенным в разделе B.2 Требования к конфигурации шины SCSI.
Для построения конфигурации шины SCSI с одним инициатором требуется:
Включить терминатор шины на каждом хост-адаптере.
Включить терминатор на RAID-контроллере.
Использовать подходящий SCSI кабель для подключения каждого адаптера к внешнему хранилищу.
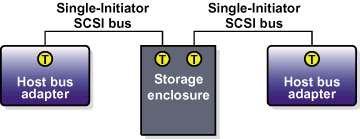
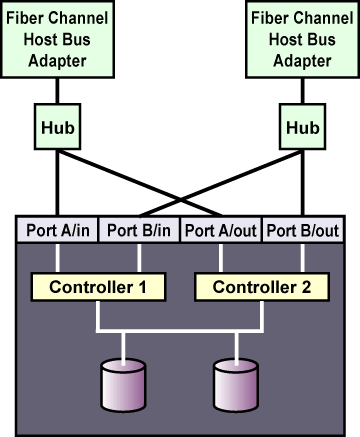
Включение терминатора на адаптере шины обычно производится в BIOS адаптера при загрузке компьютера. За указаниями по включению терминатора на RAID-контроллере, обратитесь к документации производителя. На рисунке 1-5 показана конфигурация, использующая две шины SCSI с одним инициатором.
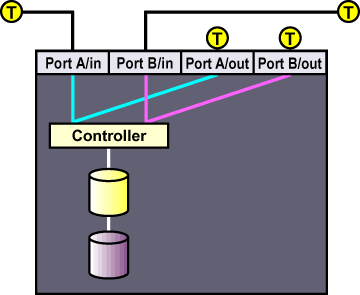
На рисунке 1-6 показано подключение терминаторов к RAID-массиву с одним контроллером, подключенным к двум SCSI-шинам с одним инициатором.
На рисунке 1-7 показано подключение терминаторов к RAID-массиву с двумя контроллерами, подключенными к двум SCSI-шинам с одним инициатором.
1.4.4.2. Настройка соединения Fibre Channel
Канал Fibre Channel может использоваться в конфигурациях с одним и с несколькими инициаторами.
Соединение Fibre Channel с одним инициатором допускает подключение только одного узла. При этом достигается большая независимость и увеличение производительности, по сравнению с шиной с несколько инициаторами. Соединения с одним инициатором гарантируют, что любой узел не зависит от большой нагрузки, инициализации или выхода из строя другого узла.
Если вы применяете RAID-массив с несколькими портами, предоставляющий одновременный доступ с разных портов ко всем общим логическим единицам устройств, используйте соединители Fibre Channel с одним инициатором для подключения к RAID-массиву всех узлов кластера. Если логическая единица устройства переносится с одного контроллера на другой, это происходит незаметно для операционной системы.
На рисунке 1-8 показан RAID-массив с одним контроллером и двумя портами, при этом хост-адаптеры подключены к RAID-контроллеру напрямую, без коммутаторов или концентраторов Fibre Channel. В случае такого соединения Fibre Channel с одним инициатором, каждому узлу кластера потребуется отдельный порт вашего RAID-контроллера.
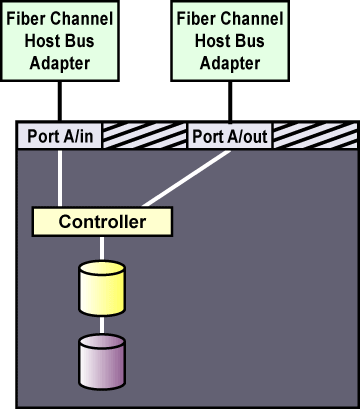
Рисунок 1-8. RAID-массив с одним контроллером, подключенный к соединителям Fibre Channel с одним инициатором
Внешний RAID-массив должен предоставить каждому узлу кластера отдельный канал SCSI. В кластерах с более чем двумя узлами, подключите каждый узел к своему SCSI-каналу RAID-массива, используя шину SCSI с одним инициатором, как показано на рисунке 1-8.
Для подключения нескольких узлов кластера к одному порту RAID-массивы, воспользуйтесь FC-коммутатором или концентратором. В этом случае, каждый хост-адаптер подсоединяется к этому коммутатору или концентратору, который, в свою очередь соединяется с портом RAID-контроллера.
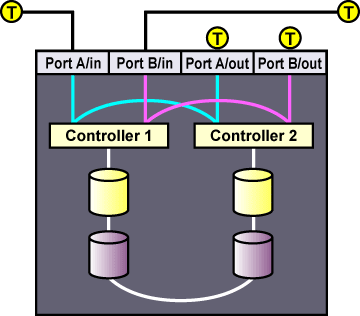
Концентратор или коммутатор Fibre Channel также потребуется для RAID-массива с двумя контроллерами, с двумя портами каждый. Эта конфигурация показана на рисунке 1-9. Дополнительные узлы кластера могут быть подключены к концентратору или коммутатору Fibre Channel, как показано на рисунке. В некоторых RAID-массивах встроен концентратор, каждый порт которого подключен к внутренним RAID-контроллерам. В этом случае, дополнительный концентратор или коммутатор не требуется.
1.4.4.3. Настройка общих разделов кластера
Для основного общего и теневого общего разделов необходимо создать на общем дисковом хранилище два неформатированных устройства. Каждый общий раздел должен иметь размер как минимум 10 Мбайт. Объём данных в кворумном разделе остаётся постоянным с течением времени.
Общие разделы используются для хранения информации о состоянии кластера, включая следующую:
Состояние блокировок кластера
Состояние служб
Информация о конфигурации
Время от времени каждый узел записывает информацию о состоянии своих служб в общее хранилище. Кроме этого, общий раздел содержит версию файла конфигурации кластера. Таким образом гарантируется, что все узлы представляют себе конфигурацию кластера одинаково.
Если основной общий раздел испорчен, узлы кластера получают информацию с теневого (резервного) общего раздела и в то же время исправляют основной раздел. Целостность данных сохраняется с помощью контрольных сумм и любые несоответствия между разделами исправляются автоматически.
Если узел не сможет при загрузке записать состояние в оба раздела, ему не будет позволено включиться в кластер. Кроме этого, если действующий узел не может выполнить запись в оба общих раздела, он сам исключит себя из кластера, перегрузившись (или может быть удалённо перегружен другим, работающим узлом кластера).
Ниже приведены требования к общим разделам:
Каждый общий раздел должен иметь размер как минимум 10 Мбайт.
Общие разделы должны быть неформатированными устройствами. Они не могут содержать файловых систем.
Общие разделы могут использоваться только для сохранения состояния кластера и информации о конфигурации.
Ниже приведены рекомендации по настройке общих разделов:
Настоятельно рекомендуется использовать для общего хранилища RAID-массивы, а для логической единицы, содержащей общие разделы, применить RAID-1 (зеркалирование). По своему усмотрению, вы можете использовать RAID-массивы с чётностью, также обеспечивающие доступность данных. Не используйте для общих разделов RAID-0 (чередование).
Располагайте общие разделы на одном наборе RAID, или, если RAID не применяется, на одном диске, так как для включения кластера оба общих раздела должны быть доступны.
Не размещайте общие разделы на диске, содержащем постоянно используемые данные. Если это возможно, разместите общие разделы на дисках, к которым службы обращаются редко.
За дополнительной информацией о создании общих разделов обратитесь к разделу 1.4.4.4 Разбиение дисков на разделы и разделу 1.4.4.5 Создание неформатированных устройств.
В разделе 2.5 Редактирование файла rawdevices вы найдёте информацию о редактировании файла rawdevices для связи неформатированных символьных устройств с блочными устройствами при загрузке системы.
1.4.4.4. Разбиение дисков на разделы
После того, как вы настроили оборудование общего дискового хранилища, выполните разбиение дисков на разделы, чтобы их можно было использовать в кластере. Затем, создайте в разделах файловые системы или неформатированные устройства. Например, для организации общих разделов должны быть созданы два неформатированных устройства, в соответствии с указаниями, приведенными в разделе 1.4.4.3 Настройка общих разделов кластера.
С помощью parted отредактируйте таблицу разбиения диска и разбейте диск на разделы. Запустив программу parted, введите команду p для отображения таблицы разбиения, а затем команду mkpart для создания новых разделов. В следующем пример показано, как с помощью parted создать на диске раздел:
Запустите parted из оболочки, выполнив команду parted и указав доступное общее дисковое устройство. В приглашении (parted) введите p для просмотра текущей таблицы разбиения. При этом на экране появится примерно следующее:
Disk geometry for /dev/sda: 0.000-4340.294 megabytes Disk label type: msdos Minor Start End Type Filesystem Flags
Определитесь, раздел какого размера вам потребуется. Создайте раздел этого размера, выполнив команду mkpart в программе parted. Хотя команда mkpart не создаёт файловую систему, обычно при создании раздела она запрашивает тип файловой системы. В parted размер раздела определяется его границами на диске; размер – это разница между концом и началом заданного диапазона. В следующем примере показано, как создать на пустом диске два раздела по 20 Мбайт каждый.
(parted) mkpart primary ext3 0 20 (parted) mkpart primary ext3 20 40 (parted) p Disk geometry for /dev/sda: 0.000-4340.294 megabytes Disk label type: msdos Minor Start End Type Filesystem Flags 1 0.030 21.342 primary 2 21.343 38.417 primary
Если на одном диске нужно создать более четырёх разделов, потребуется создать дополнительный раздел. Если вам понадобился дополнительный раздел, mkpart может создать и его. В этом случае указывать тип файловой системы не нужно.

Замечание Можно создать только один дополнительный раздел, и этот раздел должен быть одним из четырёх основных.
(parted) mkpart extended 40 2000 (parted) p Disk geometry for /dev/sda: 0.000-4340.294 megabytes Disk label type: msdos Minor Start End Type Filesystem Flags 1 0.030 21.342 primary 2 21.343 38.417 primary 3 38.417 2001.952 extended
Расширенный раздел позволяет создавать в нём логические разделы. В следующем примере показано разделение расширенного раздела на два логических.
(parted) mkpart logical ext3 40 1000 (parted) p Disk geometry for /dev/sda: 0.000-4340.294 megabytes Disk label type: msdos Minor Start End Type Filesystem Flags 1 0.030 21.342 primary 2 21.343 38.417 primary 3 38.417 2001.952 extended 5 38.447 998.841 logical (parted) mkpart logical ext3 1000 2000 (parted) p Disk geometry for /dev/sda: 0.000-4340.294 megabytes Disk label type: msdos Minor Start End Type Filesystem Flags 1 0.030 21.342 primary 2 21.343 38.417 primary 3 38.417 2001.952 extended 5 38.447 998.841 logical 6 998.872 2001.952 logical
Удалить раздел в parted можно с помощью команды rm. Например:
(parted) rm 1 (parted) p Disk geometry for /dev/sda: 0.000-4340.294 megabytes Disk label type: msdos Minor Start End Type Filesystem Flags 2 21.343 38.417 primary 3 38.417 2001.952 extended 5 38.447 998.841 logical 6 998.872 2001.952 logical
Создав все требуемые разделы, выйдите из parted, выполнив команду quit. Если раздел был добавлен, удалён или изменён при других включённых и подключенных к общему хранилищу узлах кластера, потребуется перезагрузить их, чтобы они среагировали на внесённые изменения. Разбив диск на разделы, отформатируйте разделы, прежде чем использовать их в кластере. Например, создайте файловые системы или неформатированные устройства для общих разделов. За дополнительной информаций обратитесь к разделу 1.4.4.5 Создание неформатированных устройств и разделу 1.4.4.6 Создание файловых систем.
С основами разбиения дисков при установке системы вы можете познакомиться в Руководстве по установке Red Hat Enterprise Linux.
1.4.4.5. Создание неформатированных устройств
Выполнив разбиение дисков общего хранилища, создайте на разделах неформатированные устройства. Файловые системы являются блочными устройствами (например, /dev/sda1), которые кэшируют недавно использованные данные в памяти, тем самым увеличивая быстродействие. Неформатированные устройства не используют системную память для кэширования. За дополнительной информацией обратитесь к разделу 1.4.4.6 Создание файловых систем.
Red Hat Enterprise Linux поддерживает неформатированные символьные устройства, не связанные жёстко с блочными устройствами. Вместо этого, Red Hat Enterprise Linux использует код старшего символа (в данный момент 162) для реализации набора неформатированных устройств в каталоге /dev/raw/. Любое блочное устройство может иметь соответствующее ему символьное неформатированное устройство, даже если поддержка блочного устройства загружается после загрузки системы.
Связь неформатированного символьного устройства с соответствующим блочным устройством определяется в файле /etc/sysconfig/rawdevices, в котором описывается, будет ли позволено открытие, запись и чтение данного устройства.
Общие разделы и некоторые приложения баз данных требуют применения неформатированных устройств, так как эти приложения для увеличения быстродействия выполняют собственное кэширование. Общие разделы не должны содержать файловых систем, так как, если данные о состоянии будут кэшироваться в памяти, узлы не смогут иметь полной картины состояния кластера.
Неформатированные символьные устройства должны привязываться к соответствующим блочным устройствам при каждой загрузке системы. Чтобы добиться этого, отредактируйте файл /etc/sysconfig/rawdevices и укажите привязки общих разделов. Если кластерная служба использует неформатированные устройства, также определите в этом файле необходимые привязки. За дополнительной информацией обратитесь к разделу 2.5 Редактирование файла rawdevices.
Изменения, внесённые в файл /etc/sysconfig/rawdevices, вступят в силу после перезагрузки или выполнения следующей команды:
service rawdevices restart |
Проверьте присутствие всех неформатированных устройств, выполнив команду raw -aq. При этом на экране появится примерно следующее:
/dev/raw/raw1 bound to major 8, minor 17 /dev/raw/raw2 bound to major 8, minor 18 |
Обратите внимание, кэш блочного устройства никак не связан с неформатированным устройством. Кроме этого, запросы к такому устройству должны быть выровнены по границе 512 байт и в памяти и на диске. Например, стандартная команда dd не может быть использована с неформатированными устройствами, так как буфер памяти, который передается в системную процедуру, не выровнен по границе 512 байт.
За дополнительной информацией об использовании команды raw, обратитесь к странице man raw(8).
| Замечание |
|---|---|
На всех узлах кластера нужно использовать одинаковые имена неформатированных устройств (например, /dev/raw/raw1 и /dev/raw/raw2). |
1.4.4.6. Создание файловых систем
Используйте команду mkfs для создания файловой системы ext3. Например:
mke2fs -j -b 4096 /dev/sde3 |
Для увеличения производительности общих файловых систем, определите размер блока равным 4 Кбайт, передав параметр -b команде mke2fs. При использовании блоков меньшего размера, fsck обычно работает дольше.