2. Возможности кластера
Кластер строится на следующих принципах:
Аппаратная конфигурация, не имеющая одиночной уязвимой точки.
Кластеры могут использовать RAID массив с двумя контроллерами, несколько сетевых каналов и дублирующие бесперебойные блоки питания (UPS), гарантируя таким образом, что поломка одного компонента системы не приведет к остановке кластера или потере данных.
Напротив, кластеры низкой ценовой категории не предоставляют такого высокого уровня отказоустойчивости. Например, вы можете построить кластер, используя RAID-массив, с одним контроллером, и один пульсирующий канал Ethernet.

Замечание Некоторые недорогие альтернативы, например, программный RAID или одну SCSI-шину с несколькими инициаторами, нельзя использовать для реализации в кластере общего хранилища. За дополнительной информацией обратитесь к разделу 1.1 Выбор конфигурации оборудования.
Инфраструктура конфигурации службы
Кластеры позволяют вам легко настраивать отдельные службы для обеспечения высокой степени доступности данных и приложений. Создавая службу, вы задаёте используемые ей ресурсы, её свойства, включая имя службы, сценарии запуска и остановки приложения, дисковые разделы, точки подключения, а также узлы кластера, на которых вы предпочитаете выполнять эту службу. Когда вы добавляете службу, программа управления кластером сохраняет эту информацию в файле конфигурации кластера, расположенном в общем хранилище, откуда её могут получать все узлы кластера.
Кластер предоставляет легкую в использовании инфраструктуру для приложений баз данных. Например, служба базы данных предоставляет приложению данные высокой степени доступности. Приложение, работающее на узле кластера, предоставляет сетевой доступ к базе данных своим клиентам, например Web-серверам. Если служба переносится на другой узел, приложение по-прежнему может обращаться к общей базе данных. Сетевой службе базы данных обычно назначается IP-адрес, который переносится вместе со службой, таким образом сохраняется прозрачный доступ клиентов к данным.
Инфраструктура кластерной службы также может расширяться и использоваться в других приложениях.
Отказоустойчивые домены
Привязав службу к отказоустойчивому домену с ограничением, вы можете определить узлы, на которых разрешено работать службе в случае переноса. (Служба, привязанная к отказоустойчивому домену с ограничением, не может быть запущена на узле кластера, не входящем в этот домен.) Чтобы служба выполнялась на конкретном узле (пока он работает), вы можете определить приоритеты узлов в отказоустойчивом домене. Если служба привязана к отказоустойчивому домену без ограничений, служба запускается на любом доступном узле кластера (если ни один из членов домена не доступен).
Обеспечение целостности данных
Для обеспечения целостности данных, в определённый момент времени только один узел выполняет службу и обращается к данным службы. Использование переключателей питания в конфигурации кластера позволяет одному узлу выключить другой до перезапуска его служб в процессе переноса. Это предотвращает одновременное обращение нескольких систем к одним и тем же данным, тем самым обеспечивается сохранность данных. Хотя это и не требуется, рекомендуется использовать переключатели питания для обеспечения сохранности данных при сбое в любых условиях. Сторожевые таймеры также представляют собой необязательный элемент системы управления питанием, обеспечивающий корректное выполнение операции переноса службы.
Пользовательский интерфейс управления кластером
Интерфейс администрирования кластера упрощает задачи администрирования, такие как: создание, запуск и остановку служб; перемещение служб от одного узла к другому; изменение конфигурации кластера (добавление/удаление служб или ресурсов) и наблюдение за службами и узлами кластерами.
Связывание каналов Ethernet
Каждый узел кластера постоянно проверяет состояние других узлов, опрашивая удалённый переключатель питания (если используется) и посылая пульсирующие сигналы через сетевые соединения. Связывание каналов Ethernet позволяет представить несколько Ethernet-интерфейсов как один, уменьшая вероятность отказа по сравнению с обычным Ethernet-подключением через коммутатор.
Общее хранилище информации кворума
Общая информация о состоянии помимо прочего определяет, активен ли данный узел. В информации о состоянии службы отмечается, работает ли определённая служба, и если да, то на каком из узлов. Каждый узел выполняет проверку актуальности состояния других узлов.
В кластере с двумя узлами каждый узел периодически записывает отметку времени и информацию о состоянии кластера в два общих кластерных раздела, расположенных на общем диске. Если узел при загрузке не сможет записать состояние в основной и вспомогательный общие разделы кластера, включение её в кластер не допускается, что обеспечивает корректную работу кластера. Кроме этого, если какой-то узел своевременно не изменяет свою отметку времени, и пульсирующий канал этой системы не работает, этот узел исключается из кластера.
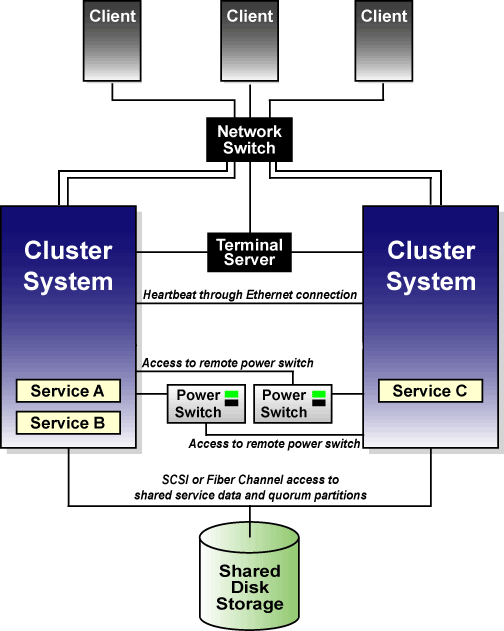
На рисунке 2 показано, как взаимодействуют узлы в конфигурации кластера. Обратите внимание, терминальный сервер, используемый для подключения к системам через последовательные порты, не является обязательным компонентом кластера.
Возможность переноса службы
Если происходит сбой программы или оборудования, кластер предпринимает действия, необходимые для поддержания доступности приложения и целостности данных. Например, если узел отказывает полностью, его службы перезапускаются на другом узле кластера или связанного отказоустойчивого домена (если он используется). Службы, уже запущенные на этом узле, при этом не затрагиваются.
Когда отказавший узел перезагрузится и сможет произвести запись в общие кластерные разделы, он снова сможет войти в кластер и выполнять службы. В зависимости от конфигурации служб, кластер может также перераспределить нагрузку между узлами.
Возможность ручного перемещения служб
Помимо автоматического переноса службы, кластер позволяет вам безболезненно вручную останавливать службы на одном узле кластера и запускать на другом. Вы можете провести плановое обслуживание узла кластера, продолжая обеспечивать доступность приложений и данных.
Возможность отслеживания событий
Кластерные демоны регистрируют события с помощью стандартной подсистемы журналирования syslog, чтобы проблемы выявлялись и решались, прежде чем они повлияют на доступность службы. Вы можете задавать уровень важности регистрируемых событий.
Наблюдение за приложением
Инфраструктура кластера может также наблюдать за состоянием и работой приложения. Таким образом, если в работе приложения произойдет сбой, кластер автоматически перезапустит это приложение. В качестве реакции на сбой приложения, приложение сначала перезапускается на том же узле кластера, а если это не исправляет ситуацию, на другом узле. Вы можете определить круг узлов, которым позволено выполнять службу, связав эту службу с отказоустойчивым доменом.